.png)
ChatTTs 最贴近真人的AI语音生成工具
如果你想寻找一款最贴近真人的AI语音生成工具,那么ChatTTS可能是你要的答案。
ChatTTS开源地址:https://github.com/2noise/ChatTTS
核心亮点:
对话式 TTS: ChatTTS针对对话式任务进行了优化,实现了自然流畅的语音合成,同时支持多说话人。
细粒度控制: 该模型能够预测和控制细粒度的韵律特征,包括笑声、停顿和插入词等。
更好的韵律: ChatTTS在韵律方面超越了大部分开源TTS模型。同时提供预训练模型,支持进一步的研究。
原始版本安装
pip install git+https://github.com/2noise/ChatTTS原始版本使用
import ChatTTS
from IPython.display import Audio
import torchaudio
<p>chat = ChatTTS.Chat()
chat.load_models(compile=False) # 设置为True以获得更快速度</p>
<p>texts = ["在这里输入你的文本",]</p>
<p>wavs = chat.infer(texts, use_decoder=True)</p>
<p>torchaudio.save("output1.wav", torch.from_numpy(wavs[0]), 24000)这样的使用方式对于普通用户,没有编程能力的用户,当然不够友好。
还好还有另一个开源UI工具,方便用户使用
https://github.com/jianchang512/ChatTTS-ui
win用户直接解压使用版本
https://github.com/jianchang512/chatTTS-ui/releases
使用限制: 英伟达显卡大于4G显存,并安装了CUDA11.8+后,将启用GPU加速
解压以后直接运行:app.exe
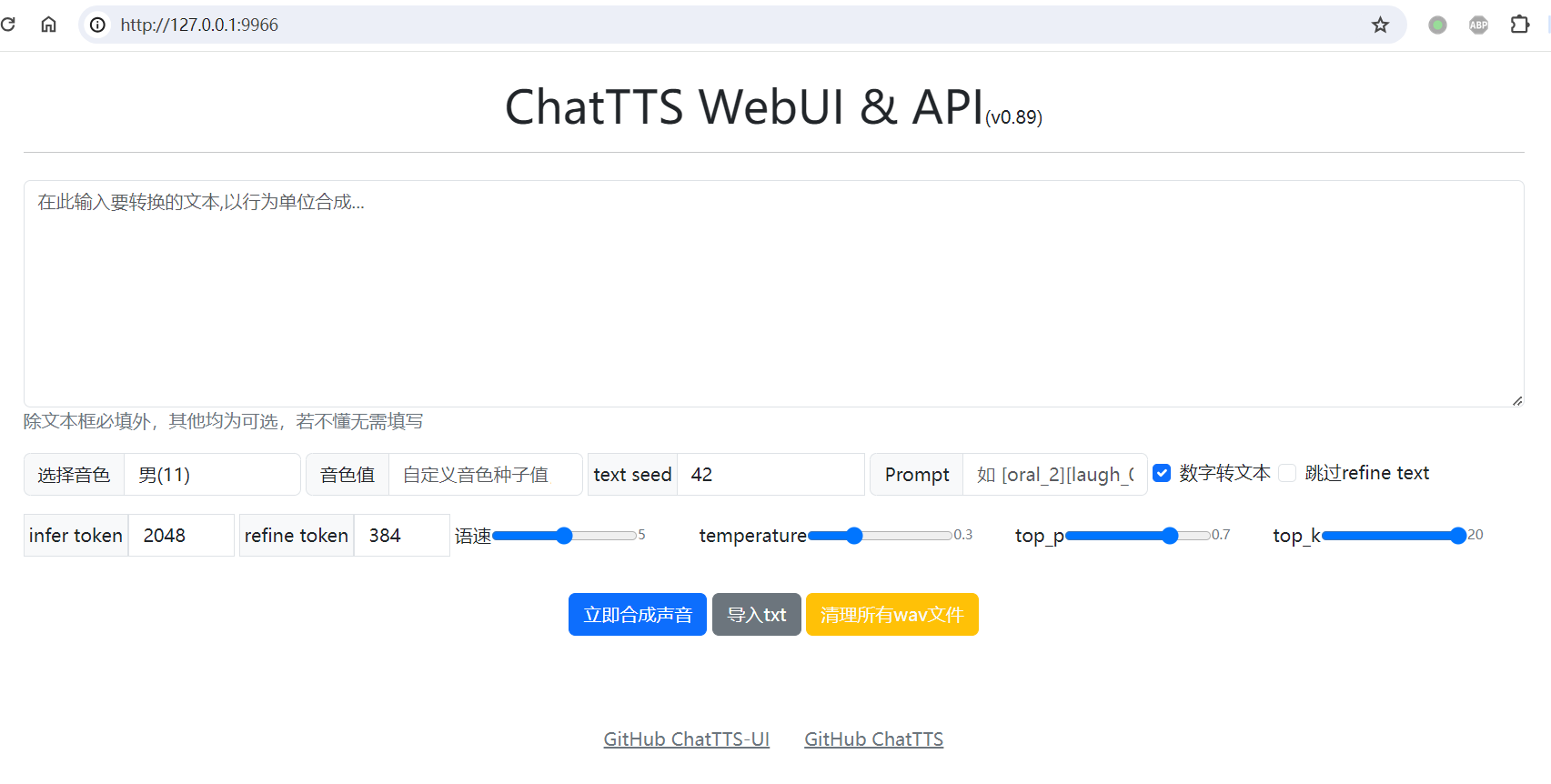
浏览器打开:http://127.0.0.1:9966/
界面介绍
输入框输入你要说的内容。
选择音色/音色值:两个概念一样,可选择的是预设置好的声音,音色值是你可以不断调整数字大小,可以选择到你喜欢的音色。
text seed:使用过Stable Diffusion的老用户都知道,这个是启始噪声值。不同值对结果有影响
prompt:用户定义固定格式的【笑声】【停顿】,目前可以忽略
跳过refine text:对文本进行修改,据说是为了更符合语境,感觉没必要。
其余参数建议保持不变。
阅读建议